
Learn to construct Llama 3.2-Imaginative and prescient domestically in a chat-like mode, and discover its Multimodal expertise on a Colab pocket book

The mixing of imaginative and prescient capabilities with Massive Language Fashions (LLMs) is revolutionizing the pc imaginative and prescient subject by way of multimodal LLMs (MLLM). These fashions mix textual content and visible inputs, displaying spectacular skills in picture understanding and reasoning. Whereas these fashions had been beforehand accessible solely through APIs, latest open supply choices now enable for native execution, making them extra interesting for manufacturing environments.
On this tutorial, we are going to learn to chat with our pictures utilizing the open supply Llama 3.2-Imaginative and prescient mannequin, and also you’ll be amazed by its OCR, picture understanding, and reasoning capabilities. All of the code is conveniently offered in a useful Colab pocket book.
Background
Llama, quick for “Massive Language Mannequin Meta AI” is a sequence of superior LLMs developed by Meta. Their newest, Llama 3.2, was launched with superior imaginative and prescient capabilities. The imaginative and prescient variant is available in two sizes: 11B and 90B parameters, enabling inference on edge gadgets. With a context window of as much as 128k tokens and help for top decision pictures as much as 1120×1120 pixels, Llama 3.2 can course of advanced visible and textual info.
Structure
The Llama sequence of fashions are decoder-only Transformers. Llama 3.2-Imaginative and prescient is constructed on prime of a pre-trained Llama 3.1 text-only mannequin. It makes use of a typical, dense auto-regressive Transformer structure, that doesn’t deviate considerably from its predecessors, Llama and Llama 2.
To help visible duties, Llama 3.2 extracts picture illustration vectors utilizing a pre-trained imaginative and prescient encoder (ViT-H/14), and integrates these representations into the frozen language mannequin utilizing a imaginative and prescient adapter. The adapter consists of a sequence of cross-attention layers that enable the mannequin to concentrate on particular elements of the picture that correspond to the textual content being processed [1].
The adapter is skilled on text-image pairs to align picture representations with language representations. Throughout adapter coaching, the parameters of the picture encoder are up to date, whereas the language mannequin parameters stay frozen to protect present language capabilities.
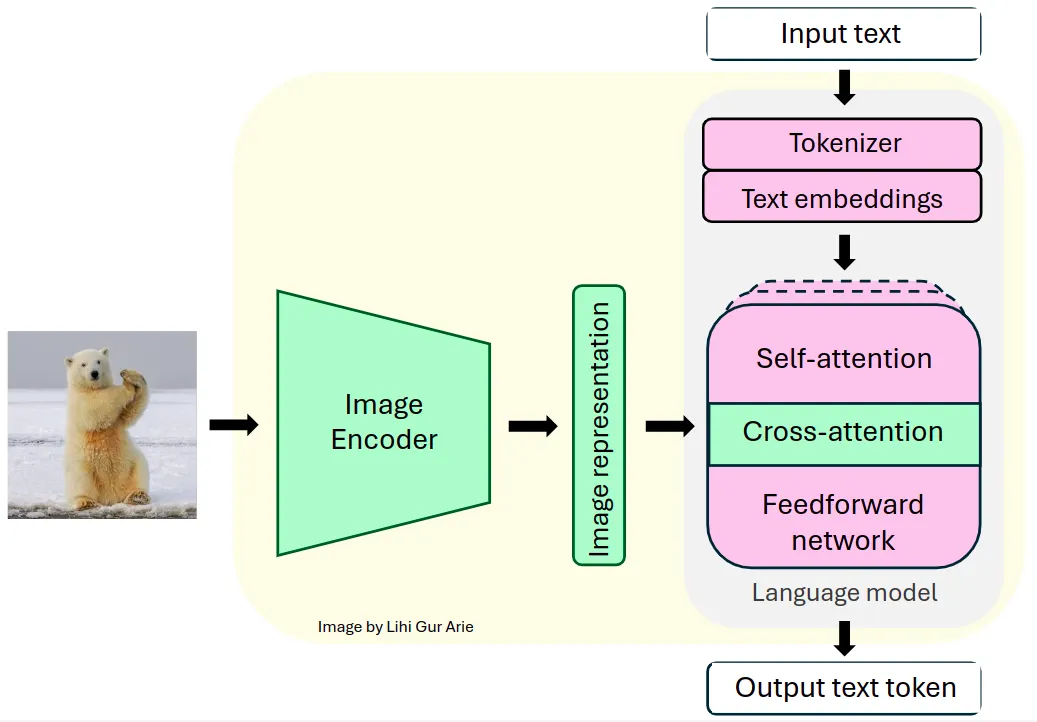
This design permits Llama 3.2 to excel in multimodal duties whereas sustaining its robust text-only efficiency. The ensuing mannequin demonstrates spectacular capabilities in duties that require each picture and language understanding, and permitting customers to interactively talk with their visible inputs.
With our understanding of Llama 3.2’s structure in place, we are able to dive into the sensible implementation. However first, we want do some preparations.
Preparations
Earlier than working Llama 3.2 — Imaginative and prescient 11B on Google Colab, we have to make some preparations:
- GPU setup:
- A high-end GPU with at the least 22GB VRAM is beneficial for environment friendly inference [2].
- For Google Colab customers: Navigate to ‘Runtime’ > ‘Change runtime kind’ > ‘A100 GPU’. Word that high-end GPU’s will not be obtainable totally free Colab customers.
2. Mannequin Permissions:
- Request Entry to Llama 3.2 Fashions here.
3. Hugging Face Setup:
- Create a Hugging Face account should you don’t have on already here.
- Generate an entry token out of your Hugging Face account should you don’t have one, here.
- For Google Colab customers, arrange the Hugging Face token as a secret environmental variable named ‘HF_TOKEN’ in google Colab Secrets and techniques.
4. Set up the required libraries.
Loading The Mannequin
As soon as we’ve arrange the setting and bought the mandatory permissions, we are going to use the Hugging Face Transformers library to instantiate the mannequin and its related processor. The processor is chargeable for making ready inputs for the mannequin and formatting its outputs.
model_id = "meta-llama/Llama-3.2-11B-Imaginative and prescient-Instruct"mannequin = MllamaForConditionalGeneration.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto")
processor = AutoProcessor.from_pretrained(model_id)
Anticipated Chat Template
Chat templates preserve context by way of dialog historical past by storing exchanges between the “consumer” (us) and the “assistant” (the AI mannequin). The dialog historical past is structured as a listing of dictionaries known as messages, the place every dictionary represents a single conversational flip, together with each consumer and mannequin responses. Consumer turns can embrace image-text or text-only inputs, with {"kind": "picture"} indicating a picture enter.
For instance, after a number of chat iterations, the messages checklist may seem like this:
messages = [
{"role": "user", "content": [{"type": "image"}, {"type": "text", "text": prompt1}]},
{"function": "assistant", "content material": [{"type": "text", "text": generated_texts1}]},
{"function": "consumer", "content material": [{"type": "text", "text": prompt2}]},
{"function": "assistant", "content material": [{"type": "text", "text": generated_texts2}]},
{"function": "consumer", "content material": [{"type": "text", "text": prompt3}]},
{"function": "assistant", "content material": [{"type": "text", "text": generated_texts3}]}
]
This checklist of messages is later handed to the apply_chat_template() methodology to transform the dialog right into a single tokenizable string within the format that the mannequin expects.
Essential operate
For this tutorial I offered a chat_with_mllm operate that permits dynamic dialog with the Llama 3.2 MLLM. This operate handles picture loading, pre-processes each pictures and the textual content inputs, generates mannequin responses, and manages the dialog historical past to allow chat-mode interactions.
def chat_with_mllm (mannequin, processor, immediate, images_path=[],do_sample=False, temperature=0.1, show_image=False, max_new_tokens=512, messages=[], pictures=[]):# Guarantee checklist:
if not isinstance(images_path, checklist):
images_path = [images_path]
# Load pictures
if len (pictures)==0 and len (images_path)>0:
for image_path in tqdm (images_path):
picture = load_image(image_path)
pictures.append (picture)
if show_image:
show ( picture )
# If beginning a brand new dialog about a picture
if len (messages)==0:
messages = [{"role": "user", "content": [{"type": "image"}, {"type": "text", "text": prompt}]}]
# If persevering with dialog on the picture
else:
messages.append ({"function": "consumer", "content material": [{"type": "text", "text": prompt}]})
# course of enter knowledge
textual content = processor.apply_chat_template(messages, add_generation_prompt=True)
inputs = processor(pictures=pictures, textual content=textual content, return_tensors="pt", ).to(mannequin.gadget)
# Generate response
generation_args = {"max_new_tokens": max_new_tokens, "do_sample": True}
if do_sample:
generation_args["temperature"] = temperature
generate_ids = mannequin.generate(**inputs,**generation_args)
generate_ids = generate_ids[:, inputs['input_ids'].form[1]:-1]
generated_texts = processor.decode(generate_ids[0], clean_up_tokenization_spaces=False)
# Append the mannequin's response to the dialog historical past
messages.append ({"function": "assistant", "content material": [ {"type": "text", "text": generated_texts}]})
return generated_texts, messages, pictures
Chat with Llama
- Butterfly Picture Instance
In our our first instance, we’ll chat with Llama 3.2 about a picture of a hatching butterfly. Since Llama 3.2-Imaginative and prescient doesn’t help prompting with system prompts when utilizing pictures, we are going to append directions on to the consumer immediate to information the mannequin’s responses. By setting do_sample=True and temperature=0.2 , we allow slight randomness whereas sustaining response coherence. For fastened reply, you may set do_sample==False . The messages parameter, which holds the chat historical past, is initially empty, as within the pictures parameter.
directions = "Reply concisely in a single sentence."
immediate = directions + "Describe the picture."response, messages,pictures= chat_with_mllm ( mannequin, processor, immediate,
images_path=[img_path],
do_sample=True,
temperature=0.2,
show_image=True,
messages=[],
pictures=[])
# Output: "The picture depicts a butterfly rising from its chrysalis,
# with a row of chrysalises hanging from a department above it."

As we are able to see, the output is correct and concise, demonstrating that the mannequin successfully understood the picture.
For the subsequent chat iteration, we’ll move a brand new immediate together with the chat historical past (historical past) and the picture file (pictures). The brand new immediate is designed to evaluate the reasoning potential of Llama 3.2:
immediate = directions + "What would occur to the chrysalis within the close to future?"
response, messages, pictures= chat_with_mllm ( mannequin, processor, immediate,
images_path=[img_path,],
do_sample=True,
temperature=0.2,
show_image=False,
messages=messages,
pictures=pictures)# Output: "The chrysalis will ultimately hatch right into a butterfly."
We continued this chat within the offered Colab pocket book and obtained the next dialog:

The dialog highlights the mannequin’s picture understanding potential by precisely describing the scene. It additionally demonstrates its reasoning expertise by logically connecting info to accurately conclude what’s going to occur to the chrysalis and explaining why some are brown whereas others are inexperienced.
2. Meme Picture Instance
On this instance, I’ll present the mannequin a meme I created myself, to evaluate Llama’s OCR capabilities and decide whether or not it understands my humorousness.
directions = "You're a pc imaginative and prescient engineer with humorousness."
immediate = directions + "Are you able to clarify this meme to me?"response, messages,pictures= chat_with_mllm ( mannequin, processor, immediate,
images_path=[img_path,],
do_sample=True,
temperature=0.5,
show_image=True,
messages=[],
pictures=[])
That is the enter meme:

And that is the mannequin’s response:

As we are able to see, the mannequin demonstrates nice OCR skills, and understands the that means of the textual content within the picture. As for its humorousness — what do you assume, did it get it? Did you get it? Perhaps I ought to work on my humorousness too!
On this tutorial, we discovered the right way to construct the Llama 3.2-Imaginative and prescient mannequin domestically and handle dialog historical past for chat-like interactions, enhancing consumer engagement. We explored Llama 3.2’s zero-shot skills and had been impressed by its scene understanding, reasoning and OCR expertise.
Superior methods could be utilized to Llama 3.2, reminiscent of fine-tuning on distinctive knowledge, or utilizing retrieval-augmented technology (RAG) to floor predictions and cut back hallucinations.
General, this tutorial gives perception into the quickly evolving subject of Multimodal LLMs and their highly effective capabilities for numerous functions.
Congratulations on making all of it the best way right here. Click on 👍x50 to point out your appreciation and lift the algorithm self worth 🤓
Need to study extra?
[0] Code on Colab Pocket book: link